原文:A crash course in just-in-time (JIT) compilers
本文译自Lin Clark 关于 WebAssembly 的卡通介绍系列,渣翻译,因此附上英文原文
- 概述:
- 背景:
- 碰撞课程:即时(JIT)编译器
- 碰撞课程:汇编
- 现在的 WebAssembly:
- 未来的 WebAssembly:
JavaScript started out slow, but then got faster thanks to something called the JIT. But how does the JIT work?
JavaScript 刚开始很慢,但是后来多亏 JIT 变得快了。但 JIT 是如何工作呢?
JavaScript 如何在浏览器中运行
When you as a developer add JavaScript to the page, you have a goal and a problem.
Goal: you want to tell the computer what to do.
Problem: you and the computer speak different languages.
当你作为开发者,向页面添加 JavaScript 时,有一个目标和一个问题:
- 目标:你要告诉电脑做什么
- 问题:你和电脑使用不同的语言
You speak a human language, and the computer speaks a machine language. Even if you don’t think about JavaScript or other high-level programming languages as human languages, they really are. They’ve been designed for human cognition, not for machine cognition.
So the job of the JavaScript engine is to take your human language and turn it into something the machine understands.
I think of this like the movie Arrival, where you have humans and aliens who are trying to talk to each other.
你说人类语言,计算机说机器语言。即使你不将 JavaScript 或其他高级编程语言视为人类语言,但它们就是。它们被设计于人的认知,而不是机器认知。
所以 JavaScript 引擎的工作就是把你的人类语言(JavaScript)转化成机器所理解的东西。
我想这就像电影 Arrival,人类和外星人试图相互交谈。

In that movie, the humans and aliens don’t just do word-for-word translations. The two groups have different ways of thinking about the world. And that’s true of humans and machines too (I’ll explain this more in the next post).
在那部电影中,人类和外星人不仅仅是做单词翻译。这两个群体对世界有不同的思考方式。人类和机器也是如此(我将在下一篇文章中解释一下)。
So how does the translation happen?
In programming, there are generally two ways of translating to machine language. You can use an interpreter or a compiler.
With an interpreter, this translation happens pretty much line-by-line, on the fly.
那么翻译如何发生呢?
在编程中,通常有两种翻译成机器语言的方法:解释器或编译器。
使用解释器,翻译几乎一行一行的进行。
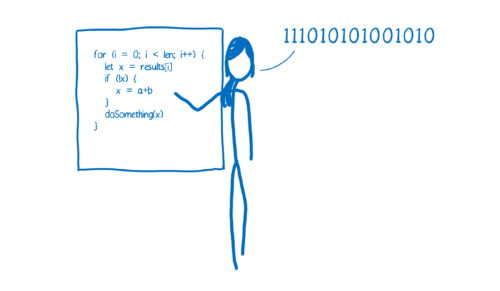
A compiler on the other hand doesn’t translate on the fly. It works ahead of time to create that translation and write it down.
而编译器并不能即时翻译,它需要提前工作来创建翻译并写下来。
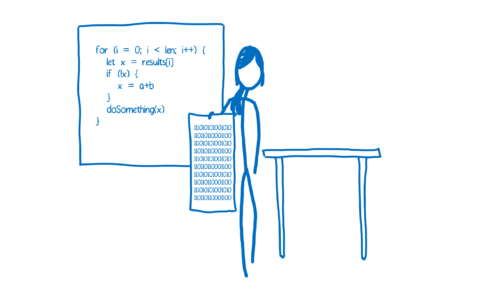
There are pros and cons to each of these ways of handling the translation.
每种处理翻译的方法都有利弊。
解释器的利弊
Interpreters are quick to get up and running. You don’t have to go through that whole compilation step before you can start running your code. You just start translating that first line and running it.
Because of this, an interpreter seems like a natural fit for something like JavaScript. It’s important for a web developer to be able to get going and run their code quickly.
And that’s why browsers used JavaScript interpreters in the beginning.
解释器可以快速启动和运行,在代码运行之前,你不需要经过整个的编译步骤。你可以直接从第一行开始翻译和运行。
正因为如此,解释器和 JavaScript 天然适合。对于Web开发人员来说,重要的是能够快速运行代码。
这就是浏览器一开始就使用 JavaScript 解释器的原因。
But the con of using an interpreter comes when you’re running the same code more than once. For example, if you’re in a loop. Then you have to do the same translation over and over and over again.
但解释器的弊端在于,当你运行同样的代码超过一次,比如你在循环中,你必须一遍又一遍地做同样的翻译。
编译器的利弊
The compiler has the opposite trade-offs.
It takes a little bit more time to start up because it has to go through that compilation step at the beginning. But then code in loops runs faster, because it doesn’t need to repeat the translation for each pass through that loop.
Another difference is that the compiler has more time to look at the code and make edits to it so that it will run faster. These edits are called optimizations.
The interpreter is doing its work during runtime, so it can’t take much time during the translation phase to figure out these optimizations.
编译器有相反的利弊。
它需要更多的时间才能开始运行,因为它在开始前需要整个的编译步骤。但是程序在循环中会运行很快,因为他不需要重复翻译循环中的每一行。
另一个不同点在于,解释器有更多的事件去产看代码并编辑,因此它会运行的更快。这些编辑称为优化。
而解释器在运行时工作,因此在翻译截断无法花费更多时间来优化。
JIT 翻译器:两个世界最好的
As a way of getting rid of the interpreter’s inefficiency—where the interpreter has to keep retranslating the code every time they go through the loop—browsers started mixing compilers in.
Different browsers do this in slightly different ways, but the basic idea is the same. They added a new part to the JavaScript engine, called a monitor (aka a profiler). That monitor watches the code as it runs, and makes a note of how many times it is run and what types are used.
浏览器解决解释器低效率——解释器每次循环时不断重新翻译——的方法,使用混合编译器。
不同的浏览器的实现方法是不一样的,但是它们的思想是一样的。它们向 JS 引擎添加了一个新部分,称之为监视器(也成为分析器)。监视器监视代码的运行,并记录运行次数以及使用类型。
At first, the monitor just runs everything through the interpreter.
首先,监视器通过翻译器运行所有内容。
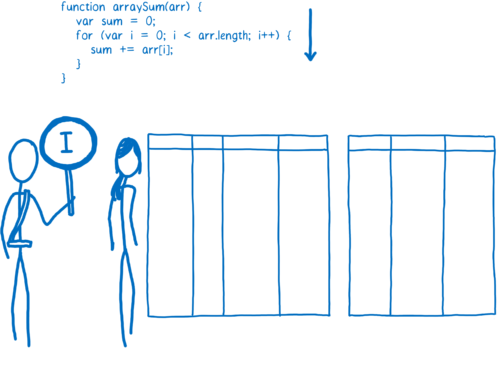
If the same lines of code are run a few times, that segment of code is called warm. If it’s run a lot, then it’s called hot.
如果同一段代码运行好几次,这段代码被称为“暖代码( warm code )” ,如果被运行多次,则称之为“热代码( hot code)”。
基线编译器(Baseline compiler)
When a function starts getting warm, the JIT will send it off to be compiled. Then it will store that compilation.
当功能开始变暖时,JIT会将其发送出去编译,然后存储该编译。
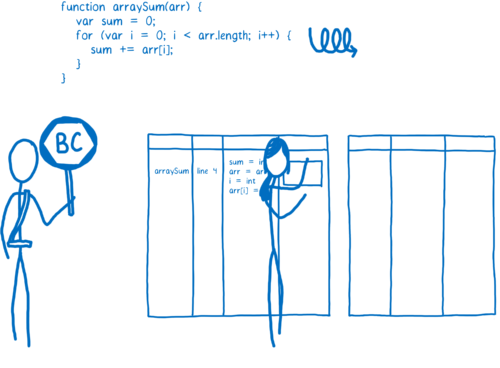
Each line of the function is compiled to a “stub”. The stubs are indexed by line number and variable type (I’ll explain why that’s important later). If the monitor sees that execution is hitting the same code again with the same variable types, it will just pull out its compiled version.
That helps speed things up. But like I said, there’s more a compiler can do. It can take some time to figure out the most efficient way to do things… to make optimizations.
函数的每一行都被编译为 Stub 。Stub 按行号和变量类型进行索引(稍后我将解释这为什么重要)。如果监视器看到使用同一变量类型的代码再次执行,那么它将拉出其编译的版本执行。
这有助于加快速度。但是像我说的那样,编译器可以做的更多。可能需要一些时间才能找出最有效的方式来做事情…来进行优化。
The baseline compiler will make some of these optimizations (I give an example of one below). It doesn’t want to take too much time, though, because it doesn’t want to hold up execution too long.
However, if the code is really hot—if it’s being run a whole bunch of times—then it’s worth taking the extra time to make more optimizations.
基线编译器将进行一些这些优化(下面给出一个例子)。但是,它不会花费太多时间优化,因为它不希望执行太久。
然而,如果代码真的 hot,如果它被运行很多次,那么它花费额外的时间进行更多的优化是值得的。
优化编译器
When a part of the code is very hot, the monitor will send it off to the optimizing compiler. This will create another, even faster, version of the function that will also be stored.
当代码的一部分非常 hot 时,显示器将发送给优化编译器,这将创建另一个甚至更快的版本,这个版本也将被存储。
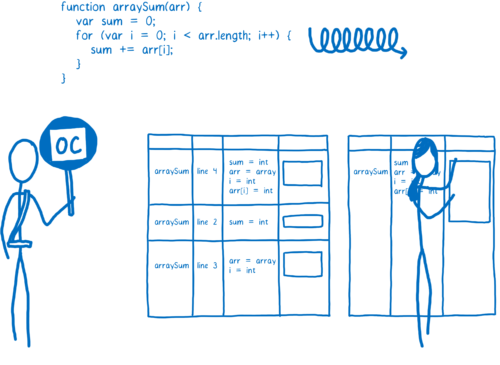
In order to make a faster version of the code, the optimizing compiler has to make some assumptions.
为了编译出速度更快的代码,优化编译器必须做出一些假设。
For example, if it can assume that all objects created by a particular constructor have the same shape—that is, that they always have the same property names, and that those properties were added in the same order— then it can cut some corners based on that.
The optimizing compiler uses the information the monitor has gathered by watching code execution to make these judgments. If something has been true for all previous passes through a loop, it assumes it will continue to be true.
例如,如果可以假定由特定构造函数创建的所有对象具有相同的特征,也就是说,它们经常会有相同的属性名,那些属性以相同的顺序添加,那么编译器可以根据这些削减一些角落。
优化编译器使用监视器收集的信息,通过观察代码执行来做出这些判断。如果所有先前的代码确实被循环执行,那么假设它将继续被执行。
But of course with JavaScript, there are never any guarantees. You could have 99 objects that all have the same shape, but then the 100th might be missing a property.
So the compiled code needs to check before it runs to see whether the assumptions are valid. If they are, then the compiled code runs. But if not, the JIT assumes that it made the wrong assumptions and trashes the optimized code.
但是,JavaScript 当然是从来没有任何保证。可能有 99 个对象都具有相同的特征,但是第 100 个可能会丢失一个属性。
所以编译的代码需要在运行之前检查以确定假设是否有效。如果是,则编译的代码运行。但如果没有,JIT 假定它做出了错误的假设,并且删除了优化的代码。
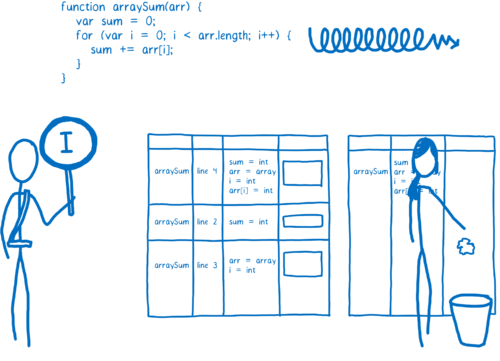
Then execution goes back to the interpreter or baseline compiled version. This process is called deoptimization (or bailing out).
Usually optimizing compilers make code faster, but sometimes they can cause unexpected performance problems. If you have code that keeps getting optimized and then deoptimized, it ends up being slower than just executing the baseline compiled version.
Most browsers have added limits to break out of these optimization/deoptimization cycles when they happen. If the JIT has made more than, say, 10 attempts at optimizing and keeps having to throw it out, it will just stop trying.
然后执行解释器或基线编译版本。这个过程叫做“去优化( deoptimization )”(或 bailing out )。
通常优化编译器可使代码更快,但有时候会导致意外的性能问题。如果你的代码不断得到优化,然后去优化,最终会比仅执行基线编译版本慢。
大多数浏览器增加了限制,以便在发生这些优化/去优化周期时停止。如果 JIT 已经超过 10 次尝试优化/去优化,那么它将停止尝试。
优化示例:类型专业化
There are a lot of different kinds of optimizations, but I want to take a look at one type so you can get a feel for how optimization happens. One of the biggest wins in optimizing compilers comes from something called type specialization.
The dynamic type system that JavaScript uses requires a little bit of extra work at runtime. For example, consider this code:
有很多不同类型的优化,但是我想看看其中一种优化,以便你可以感受到如何进行优化。优化编译器的最大优势之一来自于类型专业化。
JavaScript 使用的动态类型在运行时需要一点额外的工作。例如,考虑这个代码:
function arraySum(arr) { |
The += step in the loop may seem simple. It may seem like you can compute this in one step, but because of dynamic typing, it takes more steps than you would expect.
Let’s assume that arr is an array of 100 integers. Once the code warms up, the baseline compiler will create a stub for each operation in the function. So there will be a stub for sum += arr[i], which will handle the += operation as integer addition.
However,sum and arr[i] aren’t guaranteed to be integers. Because types are dynamic in JavaScript, there’s a chance that in a later iteration of the loop, arr[i] will be a string. Integer addition and string concatenation are two very different operations, so they would compile to very different machine code.
循环中的 += 步骤看起来很简单。看起来可以一步一步地计算出来,但是由于动态输入,所以需要比预期的更多的步骤。
我们假设 arr 是有 100 个整数的数组。一旦代码加热,基准编译器将为函数中的每个操作创建一个 stub 。所以将会有一个 sum += arr[i] 的存根,它将处理 += 操作作为整数加法。
然而,sum 和 arr[i] 不能保证是整数。因为 JavaScript 中的类型是动态的,所以在循环的后续迭代中有可能 arr[i] 将是一个字符串。整数加法和字符串连接是两个非常不同的操作,它们将编译为不同的机器代码。
The way the JIT handles this is by compiling multiple baseline stubs. If a piece of code is monomorphic (that is, always called with the same types) it will get one stub. If it is polymorphic (called with different types from one pass through the code to another), then it will get a stub for each combination of types that has come through that operation.
This means that the JIT has to ask a lot of questions before it chooses a stub.
JIT 处理这个的方式是编译多个基线 stub 。如果一段代码是单一的(也就是说,始终相同的类型调用),它将获得一个 stub 。如果它是多态的(使用不同类型调用,从一个代码调用到另一个),那么它将获得通过该操作的每种类型的组合的 stub 。
这意味着 JIT 在选择一个 stub 之前必须提出很多问题。
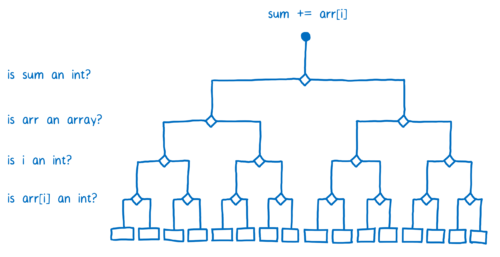
Because each line of code has its own set of stubs in the baseline compiler, the JIT needs to keep checking the types each time the line of code is executed. So for each iteration through the loop, it will have to ask the same questions.
因为每行代码在基准编译器中都有自己的一组 stub ,所以 JIT 需要在每次执行代码行时继续检查类型。所以对于循环的每次迭代,它不得不提出相同的问题。
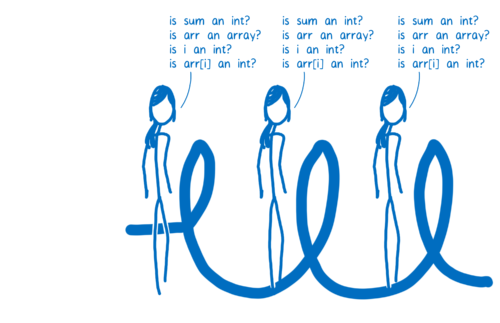
The code would execute a lot faster if the JIT didn’t need to repeat those checks. And that’s one of the things the optimizing compiler does.
In the optimizing compiler, the whole function is compiled together. The type checks are moved so that they happen before the loop.
如果 JIT 不需要重复这些检查,代码将执行得更快。这就是优化编译器所做的一项工作。
在优化编译器中,整个函数被编译在一起。类型检查被移动,以便它们在循环之前发生。
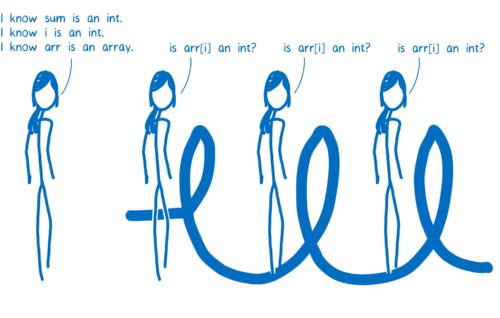
Some JITs optimize this even further. For example, in Firefox there’s a special classification for arrays that only contain integers. If arr is one of these arrays, then the JIT doesn’t need to check if arr[i] is an integer. This means that the JIT can do all of the type checks before it enters the loop.
一些 JIT 会进一步优化。例如,在 Firefox 中,只有包含整数的数组有一个特殊的分类。如果 arr 是这些数组之一,则 JIT 不需要检查 arr[i] 是否为整数,这意味着 JIT 可以在进入循环前执行所有类型检查。
总结
That is the JIT in a nutshell. It makes JavaScript run faster by monitoring the code as it’s running it and sending hot code paths to be optimized. This has resulted in many-fold performance improvements for most JavaScript applications.
这就是简单描绘的 JIT,通过监视代码的运行并发送热代码优化,使 JavaScript 运行速度更快。这为大多数 JavaScript 应用程序带来许多性能提升。
Even with these improvements, though, the performance of JavaScript can be unpredictable. And to make things faster, the JIT has added some overhead during runtime, including:
- optimization and deoptimization
- memory used for the monitor’s bookkeeping and recovery information for when bailouts happen
- memory used to store baseline and optimized versions of a function
然而,即使有了这些改进,JavaScript 的性能也不可预知。为了使运行更快,JIT 在运行时增加了一些开销,包括:
- 优化和去优化
- 消耗内存存储监视器的记录和去优化时的恢复信息
- 消耗内存存储基准和优化版本功能
There’s room for improvement here: that overhead could be removed, making performance more predictable. And that’s one of the things that WebAssembly does.
In the next article, I’ll explain more about assembly and how compilers work with it.
这里有改进的余地:可以消除开销,使性能更可预测。这是 WebAssembly 所做的事情之一。
在下一篇文章中,我将解释更多的 assembly 信息以及编译器如何和它一起工作。