原文:How JavaScript works: an overview of the engine, the runtime, and the call stack
As JavaScript is getting more and more popular, teams are leveraging its support on many levels in their stack - front-end, back-end, hybrid apps, embedded devices and much more.
随着 JavaScript 越来越受欢迎,许多团队在他们技术栈的多个方面使用它:前端,后端,混合应用程序,嵌入式设备等等。
As shown in the GitHut stats, JavaScript is at the top in terms of Active Repositories and Total Pushes in GitHub. It doesn’t lag behind much in the other categories either.
如 GitHut统计 所示,JavaScript 在 GitHub 中的活跃仓库和总推送方面位于顶部,在其他类别中也没有落后很多。
)](https://cdn-images-1.medium.com/max/1600/1*Zf4reZZJ9DCKsXf5CSXghg.png)
If projects are getting so much dependent on JavaScript, this means that developers have to be utilizing everything that the language and the ecosystem provide with deeper and deeper understanding of the internals, in order to build amazing software.
如果项目越来越依赖 JavaScript,这意味着开发人员必须利用这门语言和生态系统提供的所有内容,并且深入地了解其内部内容,以便构建出惊人的软件。
As it turns out, there are a lot of developers that are using JavaScript on a daily basis but don’t have the knowledge of what happens under the hood.
事实证明,有很多开发人员每天都在使用JavaScript,但并不知道什么情况下会发生什么。
概述(Overview)
Almost everyone has already heard of the V8 Engine as a concept, and most people know that JavaScript is single-threaded or that it is using a callback queue.
几乎所有人都已经听说过V8引擎的概念,大多数人都知道JavaScript是单线程的,或者是使用回调队列。
In this post, we’ll go through all these concepts in detail and explain how JavaScript actually runs. By knowing these details, you’ll be able to write better, non-blocking apps that are properly leveraging the provided APIs.
在这篇文章中,我们将详细介绍所有这些概念,并解释 JavaScript 如何运行。了解这些细节,你将能够正确利用提供的 API 编写更好的非阻塞性应用程序。
If you’re relatively new to JavaScript, this blog post will help you understand why JavaScript is so “weird” compared to other languages.
如果你是 JavaScript 初学者,此博客文章将帮助你了解为什么 JavaScript 与其他语言相比是如此“奇怪”。
And if you’re an experienced JavaScript developer, hopefully, it will give you some fresh insights on how the JavaScript Runtime you’re using every day actually works.
如果你是一位经验丰富的 JavaScript 开发人员,希望能为你提供一些关于你每天使用的 JavaScript 运行时实际工作的新见解。
JavaScript引擎(The JavaScript Engine)
A popular example of a JavaScript Engine is Google’s V8 engine. The V8 engine is used inside Chrome and Node.js for example. Here is a very simplified view of what it looks like:
JavaScript 引擎的一个流行示例是 Google 的 V8 引擎。V8 引擎被 Chrome 和 Node.js 使用。这是一个该引擎非常简化的视图:
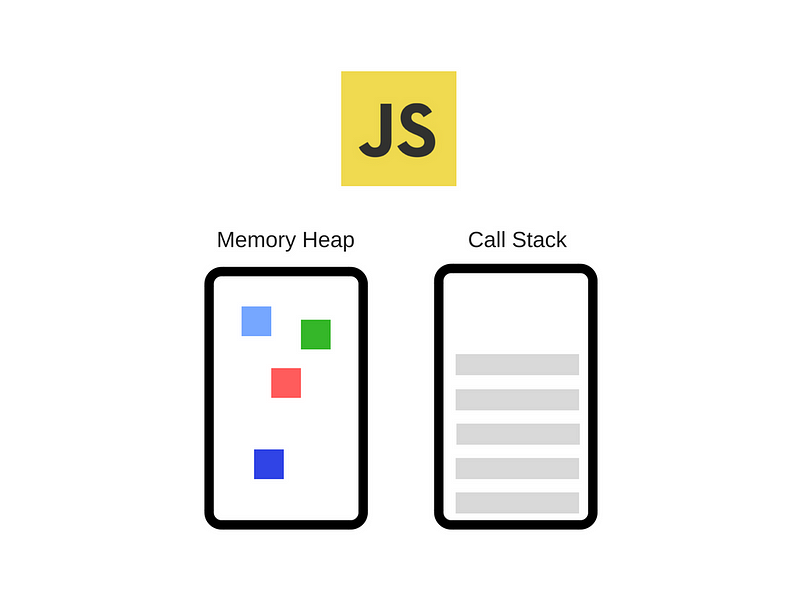
The Engine consists of two main components:
- Memory Heap - this is where the memory allocation happens
- Call Stack - this is where your stack frames are as your code executes
引擎由两个主要组成部分组成:
- 内存堆 - 这是内存分配发生的地方
- 调用堆栈 - 这是你的代码执行时堆栈帧的位置
运行时(The Runtime)
There are APIs in the browser that have been used by almost any JavaScript developer out there (e.g. “setTimeout”). Those APIs, however, are not provided by the Engine.
浏览器中已经有一些几乎被所有 JavaScript 开发人员使用的API(例如“setTimeout”)。然而,引擎不提供这些API。
So, where are they coming from?
It turns out that the reality is a bit more complicated.
那么他们从哪里来? 事实上,这有点复杂。
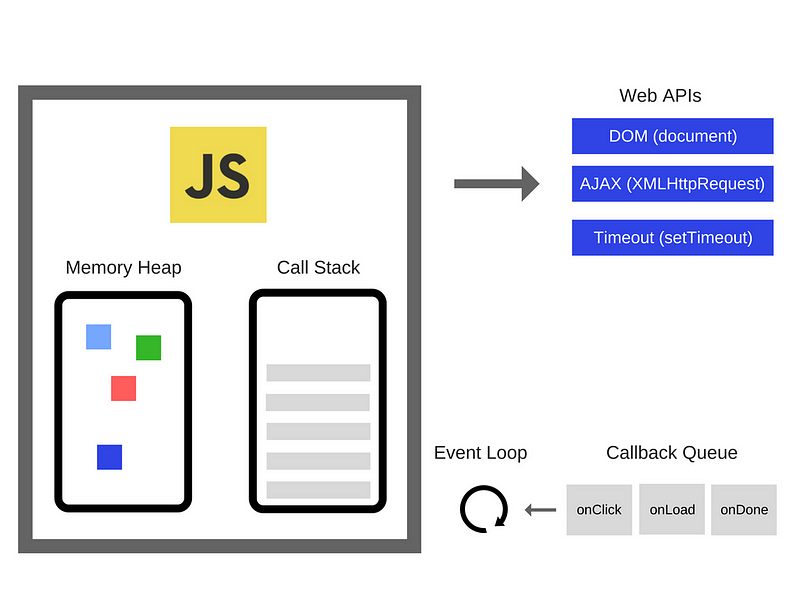
So, we have the Engine but there is actually a lot more. We have those things called Web APIs which are provided by browsers, like the DOM, AJAX, setTimeout and much more.
所以,我们有引擎,但实际上还有更多内容。有一些被称为 Web API 的东西,由浏览器提供,如 DOM,AJAX,setTimeout 等等。
And then, we have the so popular event loop and the callback queue.
然后,还有受欢迎的事件循环和回调队列。
调用堆栈(The Call Stack)
JavaScript is a single-threaded programming language, which means it has a single Call Stack. Therefore it can do one thing at a time.
JavaScript是一种单线程编程语言,这意味着它有一个单一的调用堆栈。因此,它一次只可以做一件事。
The Call Stack is a data structure which records basically where in the program we are.If we step into a function, we put it on the top of the stack. If we return from a function, we pop off the top of the stack. That’s all the stack can do.
调用堆栈是一个数据结构,它记录了我们在程序的基本位置。如果我们进入一个函数,我们把它放在堆栈的顶部。如果我们从一个函数返回,我们弹出堆栈的顶部。这就是堆栈做的事情。
Let’s see an example. Take a look at the following code:
我们来看一个例子。看看下面的代码:
function multiply(x, y) { |
When the engine starts executing this code, the Call Stack will be empty. Afterwards, the steps will be the following:
当引擎开始执行此代码时,调用堆栈将为空。之后,步骤如下
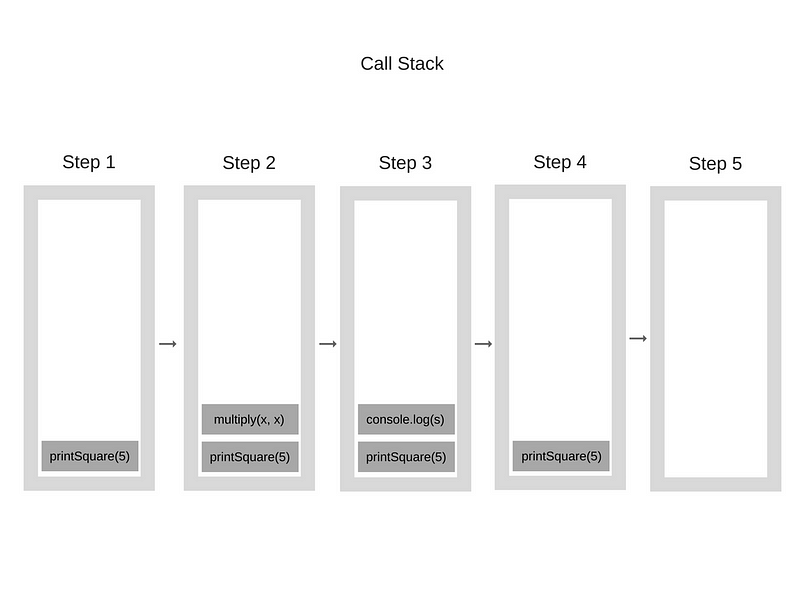
Each entry in the Call Stack is called a Stack Frame.
进入调用堆栈中的每个条目称为堆栈帧。
And this is exactly how stack traces are being constructed when an exception is being thrown — it is basically the state of the Call Stack when the exception happened. Take a look at the following code:
这正是在抛出异常时构造堆栈跟踪的方式 — 当异常发生时,它基本上是调用堆栈的状态。看看下面的代码:
function foo() { |
If this is executed in Chrome (assuming that this code is in a file called foo.js), the following stack trace will be produced:
如果这是在 Chrome 中执行的(假设此代码位于一个名为foo.js的文件中),则会产生以下堆栈跟踪:

Blowing the stack — this happens when you reach the maximum Call Stack size. And that could happen quite easily, especially if you’re using recursion without testing your code very extensively. Take a look at this sample code:
Blowing the stack — 当你达到最大调用堆栈尺寸时,会发生这种情况。这可能会非常容易发生,特别是如果你在不经过很大程度测试代码的情况下使用递归。看看这个示例代码:
function foo() { |
When the engine starts executing this code, it starts with calling the function “foo”. This function, however, is recursive and starts calling itself without any termination conditions. So at every step of the execution, the same function gets added to the Call Stack over and over again. It looks something like this:
当引擎开始执行这个代码时,它首先调用 “foo” 函数。然而,此函数是递归的,并且开始调用自身而没有任何终止条件。所以在执行的每个步骤中,相同的函数都被一次又一次地添加到调用堆栈中。看起来像这样:
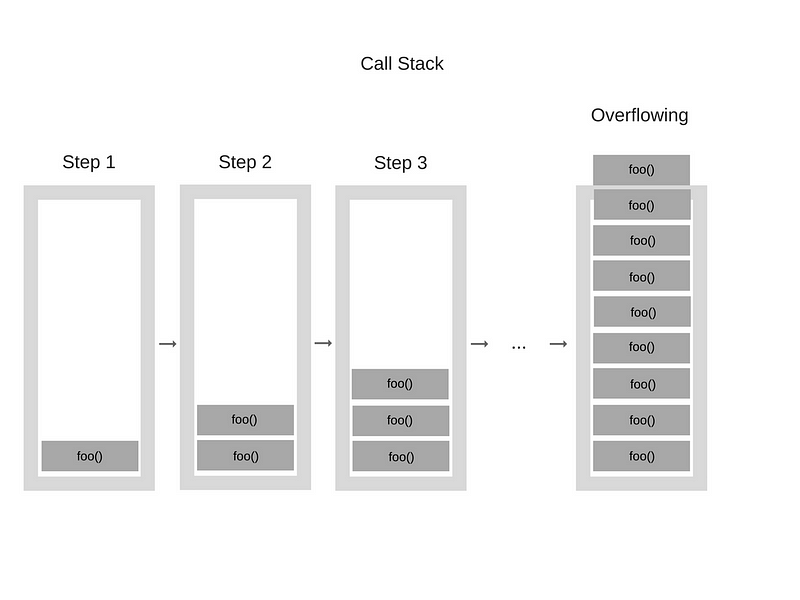
At some point, however, the number of function calls in the Call Stack exceeds the actual size of the Call Stack, and the browser decides to take action, by throwing an error, which can look something like this:
然后,在调用堆栈中的函数调用次数超过了调用堆栈的实际大小的时候,浏览器决定采取行动,抛出一个错误,看起来像这样:

Running code on a single thread can be quite easy since you don’t have to deal with complicated scenarios that are arising in multi-threaded environments — for example, deadlocks.
在单线程上运行代码可能非常容易,因为你不必处理在多线程环境中出现的复杂场景,例如死锁。
But running on a single thread is quite limiting as well. Since JavaScript has a single Call Stack, what happens when things are slow?
但在单线程上运行也是非常受限的。由于JavaScript有一个调用堆栈,当事情开始缓慢时会发生什么?
并发和事件循环(Concurrency & the Event Loop)
What happens when you have function calls in the Call Stack that take a huge amount of time in order to be processed? For example, imagine that you want to do some complex image transformation with JavaScript in the browser.
当你在调用堆栈中进行函数调用需要大量时间才能进行处理时会发生什么?例如,假设你想在浏览器中使用 JavaScript 进行一些复杂的图像转换。
You may ask — why is this even a problem? The problem is that while the Call Stack has functions to execute, the browser can’t actually do anything else — it’s getting blocked. This means that the browser can’t render, it can’t run any other code, it’s just stuck. And this creates problems if you want nice fluid UIs in your app.
你可能会问 - 为什么这是一个问题?问题在于,当调用堆栈有函数在执行的时候,浏览器实际上不能做任何事情 - 它被阻塞了。这意味着浏览器无法渲染任何内容,它也不能运行任何其他代码,它卡住了。如果你想要的UI流畅,这会产生问题。
And that’s not the only problem. Once your browser starts processing so many tasks in the Call Stack, it may stop being responsive for quite a long time. And most browsers take action by raising an error, asking you whether you want to terminate the web page.
这不是唯一的问题。一旦你的浏览器开始处理“调用堆栈”中的许多任务,它可能会停止响应很长时间。大多数浏览器通过提出错误来采取行动,询问你是否要终止网页。
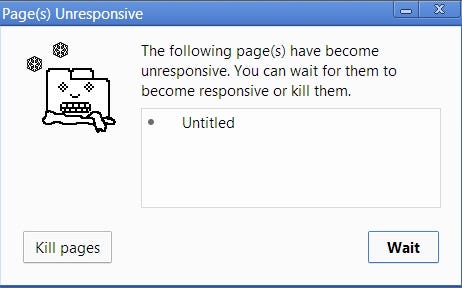
Now, that’s not the best user experience out there, is it?
这不是最好的用户体验,不是吗?
So, how can we execute heavy code without blocking the UI and making the browser unresponsive? Well, the solution is asynchronous callbacks.
那么,如何不阻塞 UI 并不造成使浏览器不响应的情况下执行繁重的代码呢?解决方案是异步回调。
This will be explained in great detail in Part 2 of the “How JavaScript actually work” tutorial. Stay tuned :)
这将在“如何JavaScript实际工作”教程的第2部分中详细解释。敬请关注 :)。